Choosing the right modeling tool for the job is one of the most critical steps in realizing ultra-efficient operations
Optima Advantage
Models and why they matter
To be an industry leader in process optimization, we understand the strengths and weakness as well as where and how to apply the most advanced modeling technologies for maximum return on investment.
The more accurate the model the more accurate the prediction but at what cost
Models are vital tools to understand, control, improve and to help train operators/maintenance personnel to optimize their processes and work flows. In essence, models are mathematical representations of the relationships between variables in (real) systems, which describe and help engineers understand the behavior of a plant or a process.
The challenging part is that models come in different shapes and sizes. They’re built using various methodologies and techniques. They offer different capabilities and benefits with different limitations. So it’s important to understand the strengths and differences of the different model types in order to build and use models that will provide the greatest advantage. The challenge is that accurately modelling real-world problems from the bottom up can get complicated quickly so being able to judiciously and adroitly build the right functionality that will provide the biggest bang for the buck is very important.
So what are the types that are most advantageous for chemical, physical and mineral process engineering? And what are their advantages and disadvantages in answering key questions such as where and how to optimize?
Let’s look at few model types in some more detail.
An industrial process response model based on isolated plant perturbations in its simplified form is represented by a first-order lag with a dead-time that represents the time delay between the application of input and the appearance of the process output.
A generic mathematical representation for a linear response looks something like this. ττ represent the time constant associated with the process response, τdτd represent the dead-time, and KK represent the process dc gain; then, simplified industrial process dynamics are represented by the following delay-differential equation:
τdy(t)dt+y(t)=Ku(t−td)(1.5.1)(1.5.1)τdy(t)dt+y(t)=Ku(t−td)
Application of the Laplace transform produces the following first-order-plus-dead-time (FOPDT) model of an industrial process:
G(s)=Ke−τdsτs+1(1.5.2)(1.5.2)G(s)=Ke−τdsτs+1
where the process parameters {K,τ,τd}{K,τ,τd}, can be identified from the process response to inputs. There are various ways to improve upon this basic equation to be able to make it more applicable to various non-linear and other difficult to model responses but the strength of this model type is that is fairly simple and inexpensive to implement. A weakness is that the process needs to be fairly well instrumented with all the process constraints clearly demarked with instrumentation.
What is Machine Learning?
As with many concepts, you may get slightly different definitions for machine learning depending on who you ask. Here are a few definitions from reputable sources:
“Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” – Nvidia
“Machine learning is the science of getting computers to act without being explicitly programmed.” – Stanford
“Machine learning algorithms can figure out how to perform important tasks by generalizing from examples.” – University of Washington
“The field of Machine Learning seeks to answer the question “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?” – Carnegie Mellon University
The strength of Machine learning is that if can provide very powerful non-linear models. The weakness is that it requires a lot of data that may only be taken infrequently or not at all.
Artificial Intelligence models have been in use in heavy industry for decades. This type of algorithm can be conceptualized as a multilinear regression where a system of weights formed by various nodes and layers provide a methodology for inferring (modeling) inputs with observed outputs from a wide array of systems. Artificial intelligence provides no insight into how or why certain outputs in a real world system are derived from the inputs it only provides a way of mimicking certain aspects of the system. Nevertheless, the modeling can be extremely helpful in trying provide tighter control because of its multivariable nature.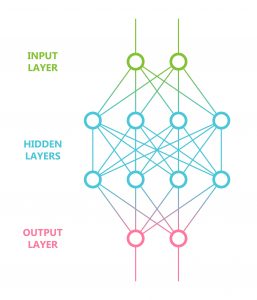
Deep learning is a machine learning technique that teaches computers to do what comes naturally to humans: learn by example. Deep learning is a key technology behind driverless cars, enabling them to recognize a stop sign, or to distinguish a pedestrian from a lamppost. It is the key to voice control in consumer devices like phones, tablets, TVs, and hands-free speakers. Deep learning is getting lots of attention lately and for good reason. It’s achieving results that were not possible before.
In deep learning, a computer model learns to perform classification tasks directly from images, text, or sound. Deep learning models can achieve state-of-the-art accuracy, sometimes exceeding human-level performance. Models are trained by using a large set of labeled data and neural network architectures that contain many layers.
Optima employees various deep learning techniques to ensure accurate and robust models for control and optimization
First principle models are built on a fundamental understanding of underlying ‘ab initio’ physio-chemical phenomena such as mass transfer, heat transfer and mass flow. Often, they’re also based on the explicit relationships in a particular unit operation within a chemical process. And they can be used to connect different unit operations by mass and heat balance in a process flowsheet.
First principle modelling has been used extensively to help design new plants. In many cases, a flow-sheet model combining first principles with correlations such as heat transfer, porosity and vapor pressure can be constructed to describe the full extent of the plant. But this can take many years (even decades) of work, lots of resources and substantial investment.
These models are often also the starting point for revamping plants, debottlenecking, or supporting and optimizing day-to-day process operations. Here, though, observed ‘real world’ data is often needed to “fill in the blanks” where parameters are unknown or missing.
The need for knowledge
First principle models depend on a lot of information, from the properties of chemicals and mixtures involved in a process to data about reactions (such as kinetics) and thermodynamics.
They also need a comprehensive, real-world knowledge of the underlying correlations, which demands expertise from different disciplines, including equipment manufacturers, process licensors and catalyst suppliers, to accurately describe a chemical operation.
Some of the information required can be found in readily available chemical engineering literature. Other, more specific data must be gathered from experiments designed with the particular process to be described in mind. This presents a challenge, though.
In real industrial scenarios, observed behavior can deviate markedly from the typical correlations we might expect to see (for instance, where chemical mixtures form azeotropes). The reason for this is that our understanding of certain phenomena – such as non-ideal mixtures, or heat and mass transfer in porous systems – is limited.
As a result, the chemical engineer’s traditional workaround has been to rely on dimensionless number approaches, such as tabulated heat-transfer correlations or vapor-liquid equilibria (cf. VDI Wärmeatlas, Dechema Datenbank). And the workarounds don’t stop there.
The problem with parameters
All first principle models rely on adequate parameters, applicable to the specific process they’re describing or the problem they exist to solve. Getting them is easier said than done.
One of the big challenges in accessing the information needed is that, in looking beyond base effects to the secondary effects that also influence the chemical process, accessibility through (direct) measurements decreases as the complexity and number of parameters involved increases.
Accurately modelling real-world problems from the bottom up can get complicated quickly, as accessing the right measured parameters gets more and more challenging.
Despite decades of research to try to close these gaps, uncertainty remains and phenomena observed in real-world industrial systems still cannot be sufficiently described. It’s easy to end up with thousands of model equations, often coupled with partial differential equations, that cannot be solved analytically. In many cases even solving them numerically is a major challenge. So “fiddle factors” have come into play.
These are parameters used to fit model outputs to the observed data, or to design and safety margins in a plant’s design. Essentially, they compensate for unknowns or uncertainties in the models and, arguably, inadequacies in the first principle approach as a whole. But such approximations can leave significant inaccuracies in the final result, meaning all effects cannot be confidently captured to their full extent.
In search of an easier answer
We should note that pretty much anything can be modelled in this way, and deliver a number of reasonable qualities, if enough time, budget and energy is invested in doing so. But, with its reliance on engineering handbooks, the validity of the first principle approach will always be limited.
Knowledge-based models need to deliver on several fronts if they’re to help design new plants, revamp old ones, reduce bottlenecks or drive process efficiency. They must have ample scope for extrapolation. Provide a smooth, continuous, and differentiable foundation for optimization. And, in environments where major changes in processes, equipment and catalysts are likely, they must adapt easily and be constantly reviewed to keep them up to date.
Is all of the traditional effort of first principle really needed in order to optimize a chemical process? After all, an existing plant is defined by properties such as its installed equipment or catalysts. And its behavior can be described by data measured within it.
As such, the extrapolation capabilities usually needed to design a new plant wouldn’t be required to model or describe the process, at least within the scope of existing data. And surely data captured from the process is the asset that offers the greatest scope to learn what’s needed to optimize?
The term fuzzy logic was introduced with the 1965 proposal of fuzzy set theory by Lotfi Zadeh.[2][3] Fuzzy logic had, however, been studied since the 1920s, as infinite-valued logic—notably by Łukasiewicz and Tarski.
Fuzzy logic is based on the observation that people make decisions based on imprecise and non-numerical information. Fuzzy models or sets are mathematical means of representing vagueness and imprecise information (hence the term fuzzy). These models have the capability of recognizing, representing, manipulating, interpreting, and utilizing data and information that are vague and lack certainty. – Wikipedia
Even thought not technically a modeling tool, fuzzy logic and its cousin expert rules have been tried for decades in the mineral processing industry with only limited success.
Hybrid models: the best of all possible worlds
Some of the disadvantages and limitations of the models presented above and below can be overcome using hybrid models.
Hybrid models come in various shapes and sizes too. What they have in common is they still rely on first principle domain knowledge to one degree or another, but combine that with statistical methods where the knowledge needed is lacking or doesn’t sufficiently describe reality.
The use of data-driven neural networks and hybrid models to dynamically model chemical reaction systems was being described 20 years ago. Using them successfully, though, is more of a skill. It’s important to identify upfront the hybrid models genuinely capable of delivering the goals they’re designed to achieve – such as process optimization, process operations training etc.
In today’s mineral processing and chemical plant operations, optimization is guided mostly by operators’ and engineers’ knowledge and experience, but what if you could optimize on a continuous and ongoing basis ? You can. Digitalization and the latest technologies are already offering mineral processors and chemical producers the scope to make profitable advances in this area.
We make models do more
Optima takes a unique approach to find untapped potential in your mineral processing or chemical processes. We’ve developed next-generation hybrid process models that can adapt easily to your plant’s historic and real-time data, to generate reliable setpoints to continuously optimize your operations, provide operator simulators, what-if offline diagnostic tools etc.
These hybrid models still use established first principle techniques, physico-chemical relationships and engineering principles as a basis for predictions. Therefore this ensures that the mass balance is closed and cause-effect relationships in the process, such a residence times, are correctly captured.
The first step in creating a hybrid model is to identify or create a process-specific base model constructed using chemical engineering know-how. Once a meaningful base model is built that matches the basics of the process we can then turn to the process data itself to measure and optimize performance.
It’s the process data that reflects the the process itself that really makes a big differences in the accuracy and robustness of a hybrid models. By carefully integrating unknowns using meticulously curated process operations data, our models ensure an excellent fit for all data they observe and form a solid foundation for extrapolation and optimization.
We take great care to make sure all relevant nuances in your process are captured and considered, then apply advanced machine learning techniques. This creates AI-enhanced, data-driven, hybrid process models that, in contrast to rigid and inflexible first principle models, can learn intuitively and adapt quickly to changing conditions.
This attention detail means your Optima engineered optimizing controller can act quickly and with confidence on real-time recommendations to reach your optimization goals and meet your most pressing KPIs.
Let’s compare two types of models/controls in common use in the mining industry these days The left column highlights the use of response models for multivariable control. On the right, expert and fuzzy rules used for modeling and control are discussed.